Job Seek Development Journal - 1
Job seeker started when wherewot projects were about to finish. The first version of it was wrote in python. Now I want to refactor it with .net core stack due to its simplicity and powerful features.
The purposes of this toy project is very simple,
- Find jobs in employment websites based on search query
- Automatically generate Cover letters and CVs in terms of the profile and job details
- Analyse the user inputs and job market and try to give useful statistics
The python version I wrote before is only for personal usage, I was always told ‘dream bigger’. So this version, I am going to extends its scalability by turning into a C / S cloud application.
tl;dr – initial design contains many mistakes
Feasibility and possible technique sets
The figure below displays the simple DDD four layer structure and the main technique stacks required within them. Despite many need-to-learn knowledge especially the .net core stack and rabbitmq, most of concepts and design pattern in the project are not new for me.
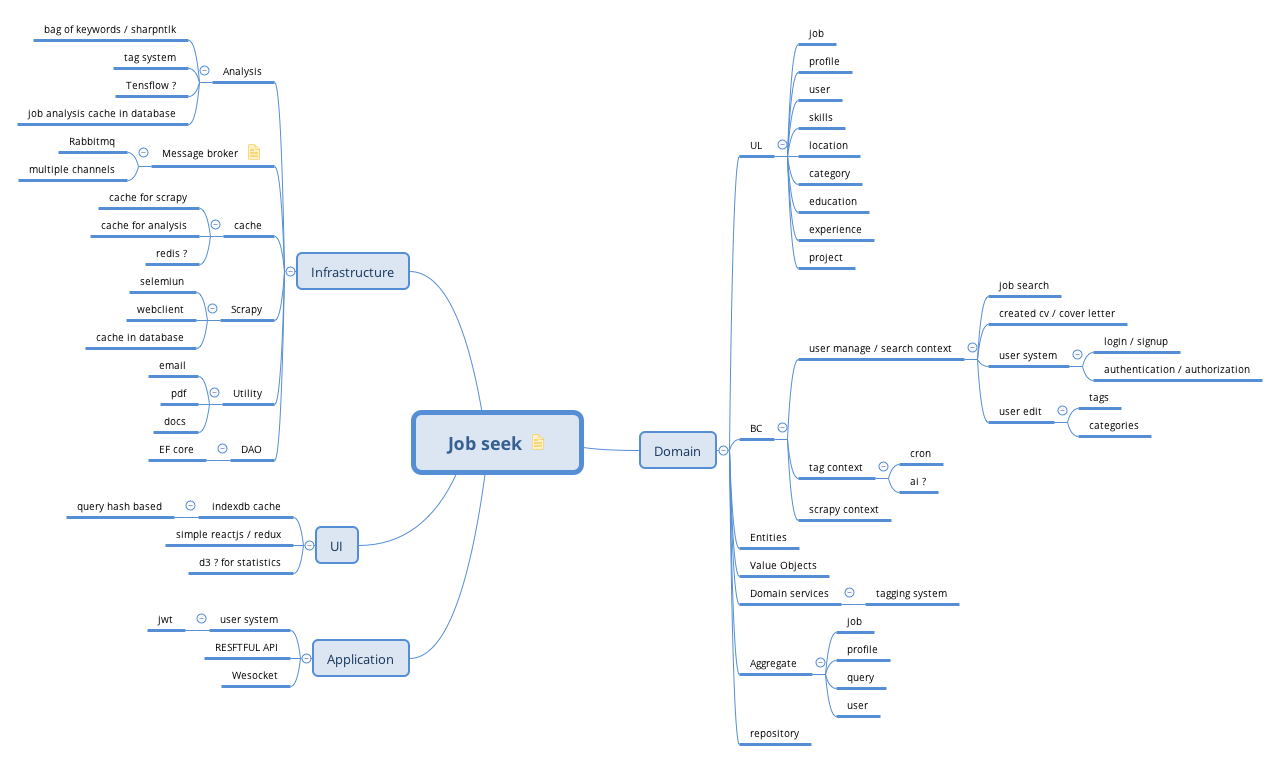
Main architecture
I will use CQRS for the main pattern1, because:
- isolate read and write
- Might need to query vast statistic data
- Async write and EDA needed
- There are many time consuming tasks in the project: web crawling / email / pdf and docs generating
- Main search and return function – send job one by one back to user in websocket requires EDA
- The analyse tasks such as tagging will use lots of write IO and require EDA
- multiple level of caches
- Only need eventually consistency
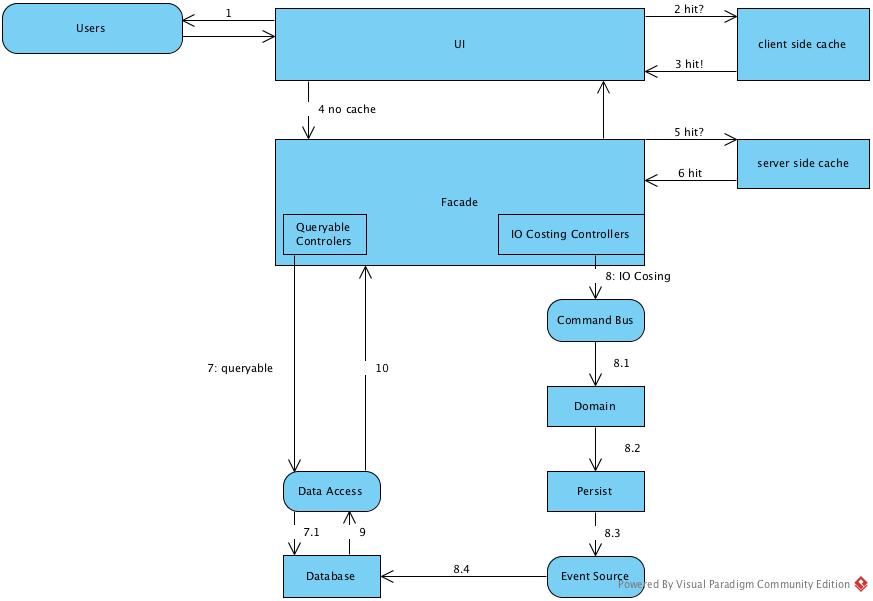
The main process of this job seek would be:
- When user open any ends, a websocket connection will be established.
- The server will initialize jwt, message broker and other server resource
- Then depends on the actions user started, the controller will decide to go through command bus or directly query database.
Domain define
Despite not been an expert in job seeking area, from my view and google search results, the job advertise is a collection of requirements which need to be fulfilled based on personal profiles in other words, the skills* set, **work experience, personal projects, activities and son. The job itself contains information that user might interested: working environment, location, salary and so on. This is a two way process.
Bounded contexts
- user manage / search context
A user can input query to search and expect to get the tagged jobs and formated cv / cover letter. Moreover, a user can also update profile information and view jobs, cvs, statistics and so on
- tag context
Tag context is responsible for analyzing and tagging many assets in job seek, eg jobs, requirements, projects, educations and so on.
- scrapy context
This is for crawling the employment websites in two steps, crawl the list pages and scrapy the detailed page.
Context map
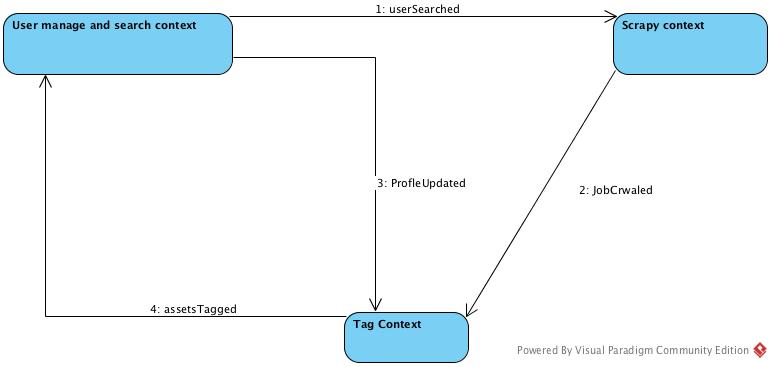
- Events for user searched jobs
- Events for crawler successfully get the detailed jobs
- Events for user updated profile
- Events for assets been tagged
UL
- user: someone who use job seek
-
query: includes keywords and location
- job: the posted job in the job market website
- requirements: the requirement in a job
- employer: just employer
-
category: job category
- location: location contains address and latitude / longitude
- locality: locality with postcode
- state: state
-
country: country
- profile: a collection of user information, skills, education, experience, projects and so on
- skills: skills
- experience: working experience
- projects: user projects
-
activities: user activities
- tags: identifier and corner store in the project
-
keywords: just keywords
- user: login user and non login user
- role: role
- assets: cvs, cover letters, applied jobs
- token: json web token for user
Entity
- job
- user
- profile
- experience
- projects
- educations
- activities
- otherItems
Value Object
- tag
- query
- keyword
- category
- skills
- requirements
- location
- locality
- state
- country
- employer
Aggregate and repository
- query
- query as aggregate root
- value objects: keywords, location
- tagged jobs
- job
- job as aggregate root
- value object: requirements, tags, etc
- profile
- profile as aggregate root
- tagged projects
- tagged jobs
- tagged educations
- value objects: skills, location, etc
- user
- user as aggregate
- tagged profile
- CVS / Cover Letters
- Applied jobs
Domain services
- tagging
- the evolutionary tagging algorithm will lead to different version of tagged assets
- value objects deep level tagging will be a cron job
table relation tl;dr
As this is a small system, I will give the simple table models to indicate the whole relations among entities and value objects.
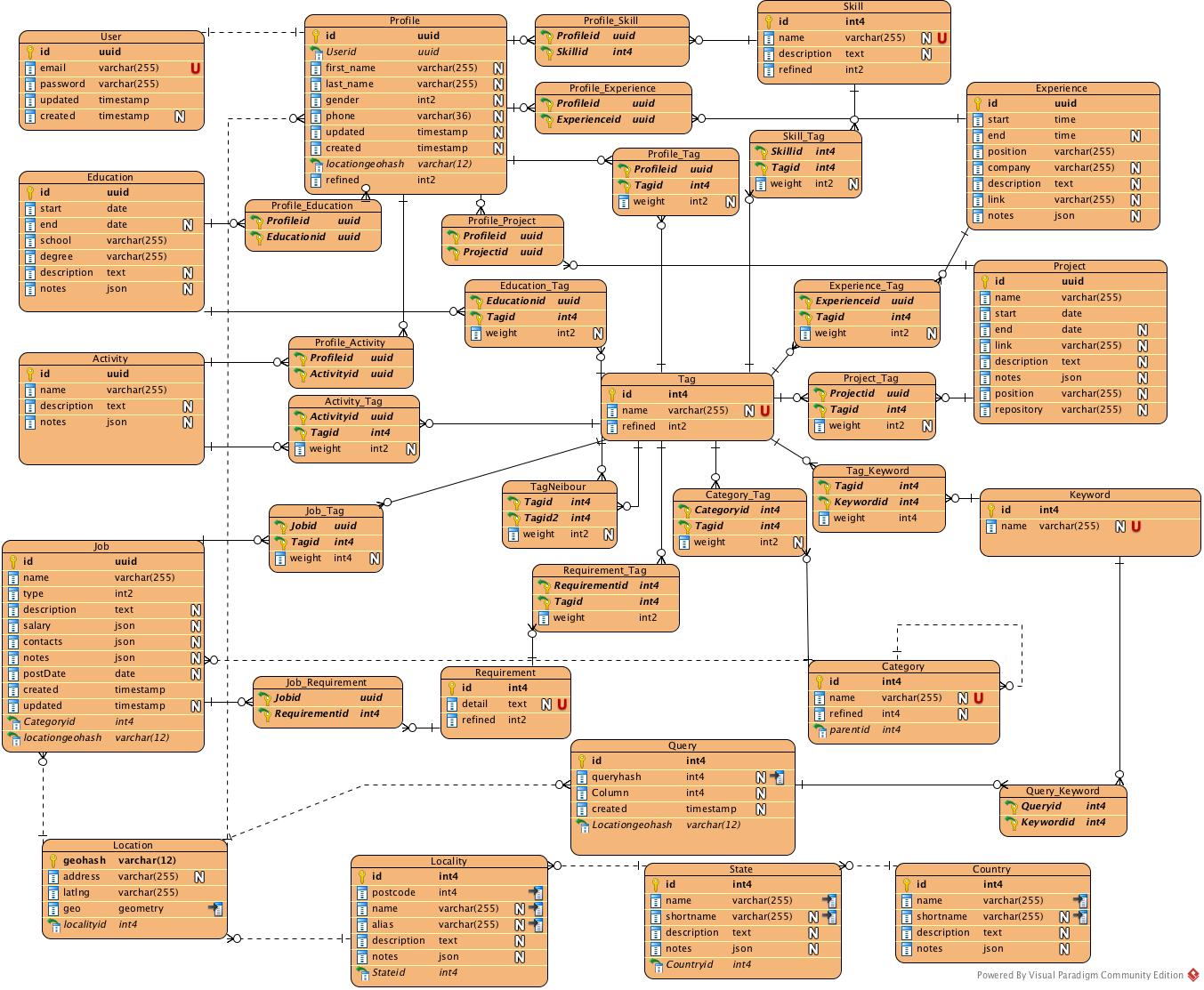
As can been seen from the db table below, job seek is highly replied on tag system. All every value objects and some profile related entities are tagged with a weight. Moreover, depending on the evolution of tag algorithm, the tag system would continuously refine the results.
Conclusion
I struggled to squeeze job seek into DDD concepts behind the door and this is also a learning journey so the design above is incomplete. However, it is necessary to record my thoughts on DDD for the future review.
To begin with, I think DDD is very useful for business software development which brings developers, customers, experts together as:
- DSL enable developer effectively communicate the model with both other developers and non-programmers
- Domain oriented enable changes from source stay in the domain and will not be misunderstood
- Force developer think closer to real world
- effective way of organizing cases
The reasons I choose DDD and CQRS are some problems raised when I developed simple python version for one client.
- performance issue on scrapy and tagging
For scrapy, I separated the list crawling and detailed crawling and use job pools for communication. As for tagging, I pre-tagging my own profile and used simple bag of keywords for job tagging. Moreover, cached every steps.
If it became a C / S or B / S app, the concept will be same, but there would be some major difference:
- Message broker for communication
- scrapy for job list is personal and detailed job crawling should shared among users.
- Different tagging strategies for different assets
- cache for different level and size.
Then I found CQRS which seems to fit in my needs, especially the events source and isolation of writing and reading. For now, I plan not persist all the events as seems to be unnecessary in the system. But any way, it is just a draft of my first thought. There is long journey to go for the simple function to work.
Reference
-
Microsoft 2018, CQRS Journey and guide, https://msdn.microsoft.com/en-us/library/jj554200.aspx ↩